SQL GROUP BY, HAVING, ORDER BY
1. GROUP BY
- 특정 컬럼(표현식)을 기준으로 행을 그룹화하여 단일행으로 표기
- 실제 출력되는 행 수가 그룹화로 인해 줄어듦

- 주의사항 GROUP BY 를 사용한다면, GROUP BY 에 명시되지 않은 컬럼은 SELECT에 이용할 수 없다.

- 리터럴은 GROUP BY 에 입력된 컬럼에 상관없이 출력될 행 수 만큼 출력

- 집계함수(다중행 함수)를 사용 가능
특정 컬럼 등을 기준으로 해서 그룹화를 하고 개수를 세거나 , 최대값 , 평균값 등을 구함
| COUNT() | 그룹별로 행의 개수 출력 * 사용 가능하며,NULL을 포함한 행의 개수 출력 컬럼을 명시하면 NULL을 무시하고 개수 출력 |
| MAX(), MIN() | 그룹별 최댓값, 최솟값 NULL 데이터 무시 날짜형, 문자형, 숫자형 모두 적용 가능 |
| AVG() | 그룹별 평균값을 구해 출력 NULL 데이터 무시 (입력되는 행이 모두 NULL이면, NULL 출력) 숫자형만 사용 가능 |
| SUM() | 그룹별 합계값 출력 NULL 데이터 무시 (입력되는 행이 모두 NULL이면, NULL 출력) |
※ 연습 데이터 추가
UPDATE 학생인적사항 SET 키 = NULL WHERE 학급ID IS NULL ;
UPDATE 학생인적사항 SET 학급ID = 'F' WHERE 학급ID IS NULL ;
COMMIT;
① COUNT()
SELECT 학급ID
, COUNT(*)
FROM 학생인적사항
GROUP BY 학급ID;
SELECT 학급ID
, COUNT(키)
FROM 학생인적사항
GROUP BY 학급ID;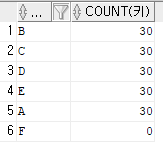
※ GROUP BY를 사용하지 않아도 집계함수 자체는 사용 가능 (테이블 모든 행을 하나의 그룹으로 판단)
SELECT COUNT(*)
FROM 학생인적사항 ;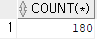
SELECT COUNT(키)
FROM 학생인적사항 ;
② MAX(), MIN()
직원 테이블 내 최대연봉, 최소연봉
SELECT MAX(연봉) AS 최대연봉
, MIN(연봉) AS 최소연봉
FROM 직원;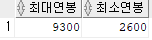
직원 테이블 내 부서별 최대연봉, 최소연봉
SELECT 부서ID
, MAX(연봉) AS 최대연봉
, MIN(연봉) AS 최소연봉
FROM 직원
GROUP BY 부서ID;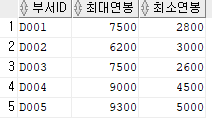
학생인적사항 테이블 내 학급ID별 가장 큰 키, 작은 키 (모든 값이 NULL이면, NULL 출력)
SELECT 학급ID
, MAX(키)
, MIN(키)
FROM 학생인적사항
GROUP BY 학급ID;
③ AVG()
학생인적사항 테이블 내 각 학급별 키의 평균값을 구해 소수점 1번째 자리까지 출력
SELECT 학급ID
, ROUND(AVG(키), 1) AS 평균키
FROM 학생인적사항
GROUP BY 학급ID;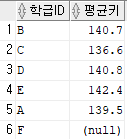
④ SUM()
직원 테이블 내 전체 직원의 연봉 합계
SELECT SUM(연봉) AS 연봉합계
FROM 직원;
직원 테이블 내 부서별 직원의 연봉 합계
SELECT 부서ID
, SUM(연봉) AS 연봉합계
FROM 직원
GROUP BY 부서ID ;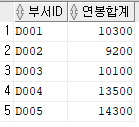
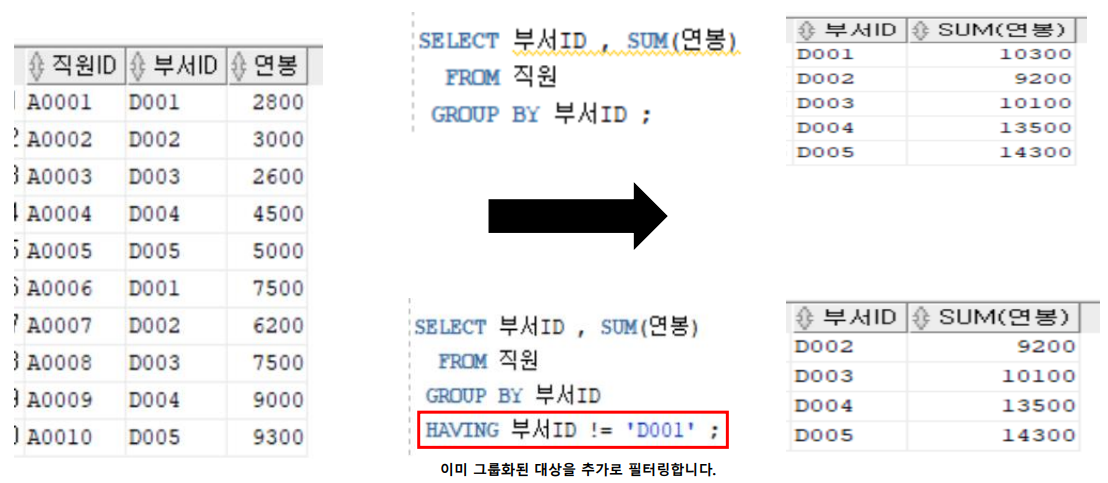
2. HAVING
- GROUP BY로 그룹화가 완료된 후에 대상을 필터링하는 문법
- 집계 함수에 조건을 줄 수 있음 (WHERE는 집계 함수 사용 불가)
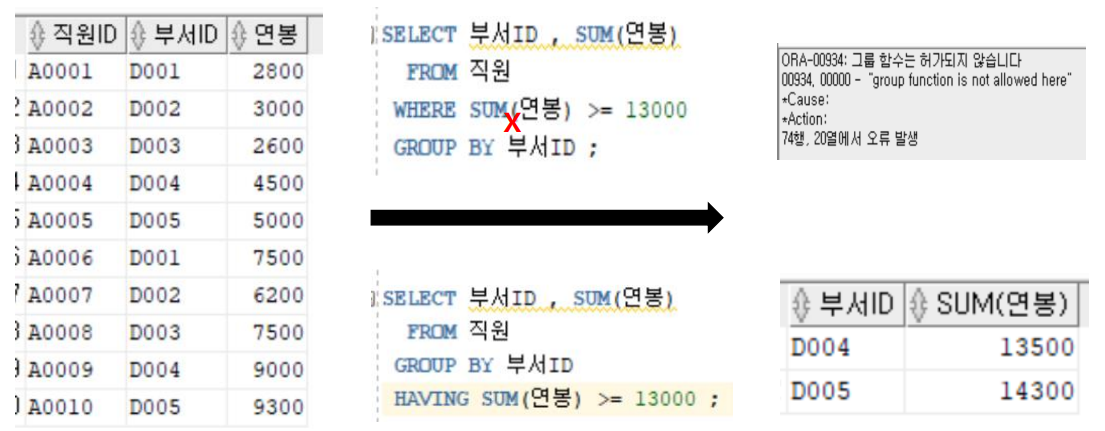
- WHERE는 GROUP BY보다 먼저 실행되고, HAVING GROUP BY보다 나중에 실행


- WHERE → GROUP BY → HAVING순서이므로 HAVING은 GROUP BY의 영향을 받는다. 따라서 GROUP BY에 입력된 컬럼에 의해서 입력 가능한 컬럼의 제약을 받게 된다.

※ 쿼리의 실행 순서

① 직원 테이블 접근
② 부서ID가 ‘D001’ , ‘D002’ , ‘D003’ 인 튜플만 대상으로 필터링
③ 부서ID 컬럼을 기준으로 그룹화
④ 그룹화가 완료된 튜플에서 SUM(연봉) 이 10000 이상인 대상을 필터링
⑤ 부서ID 컬럼과 SUM(연봉) 집계값을 출력
3. ORDER BY
- 특정 컬럼을 기준으로 데이터 집합을 오름차순 혹은 내림차순 정렬
① 오름차순 정렬
예시) 직원 테이블의 모든 데이터를 출력하고, 이름을 기준으로 오름차순 정렬
SELECT *
FROM 직원
ORDER BY 이름;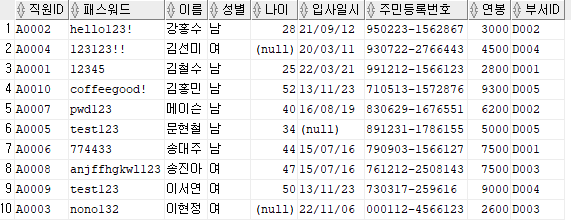
② 내림차순 정렬
예시) 직원 테이블의 모든 데이터를 출력하고, 연봉을 기준으로 내림차순 정렬
SELECT *
FROM 직원
ORDER BY 연봉 DESC;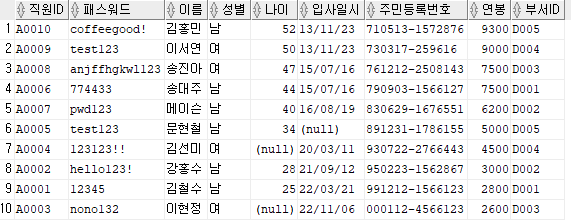
③ 정렬 기준 2개 이상 가능
예시) 직원 테이블의 모든 데이터를 출력하고, 부서ID 를 기준으로 오름차순 정렬, 부서ID가 동일할 경우에는 연봉을 기준으로 내림차순 정렬을 하여 출력
SELECT *
FROM 직원
ORDER BY 부서ID
, 연봉 DESC ;
- SELECT로 데이터가 추출된 이후에 실행되며, SELECT에 입력되지 않은 컬럼도 사용 가능

- GROUP BY가 명시된 경우에는 GROUPY BY에 의해 한정된 컬럼만 사용 가능

- 컬럼 이름 이외에도 ALIAS, 숫자 등으로도 표시 가능

▶ 실습
①직원 테이블과 직원 연락처 테이블을 이용해서 직원별로 연락처정보가 몇개 있는지 확인
직원 테이블을 기준으로 A0001 ~ A0010 의 모든 직원을 보여주되 , 연락처가 없는 대상도 0건으로 출력
오라클 방식 조인 사용
예시)
직원 A0001 은 집전화, 휴대폰 둘다 가지고 있으므로 2개의 연락처 정보
직원 A0006 은 휴대폰 만 있으므로 1개의 연락처 정보
직원 A0009 은 연락처 정보가 없어서 0건을 표시
SELECT A.직원ID
, COUNT(B.연락처) AS 연락처개수
FROM 직원 A
, 직원연락처 B
WHERE A.직원ID = B.직원ID(+)
GROUP BY A.직원ID;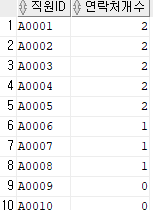
② 1번의 쿼리를 그대로 이용하되, COUNT(B.연락처) 의 개수가 0개인 직원만 추출
SELECT A.직원ID
, COUNT(B.연락처) AS 연락처개수
FROM 직원 A
, 직원연락처 B
WHERE A.직원ID = B.직원ID(+)
GROUP BY A.직원ID
HAVING COUNT(B.연락처) = 0;
③ 2번의 문제를 그대로 이용하되, 직원ID 가 'A0009'인 대상만 출력되도록 추가적인 필터링
SELECT A.직원ID
, COUNT(B.연락처) AS 연락처개수
FROM 직원 A
, 직원연락처 B
WHERE A.직원ID = B.직원ID(+)
GROUP BY A.직원ID
HAVING COUNT(B.연락처) = 0
AND A.직원ID IN 'A0009';
④ 직원테이블에서 부서ID 별로 연봉이 가장 높은 대상과 연봉이 가장 낮은 대상을 출력하고, 동시에 두 값의 차를 구해서 AS 연봉차이 출력
SELECT 부서ID
, MAX(연봉) AS 최대연봉
, MIN(연봉) AS 최소연봉
, MAX(연봉)-MIN(연봉) AS 연봉차이
FROM 직원
GROUP BY 부서ID;
⑤ 4번 쿼리를 그대로 사용하되 , 최대연봉차이가 4500 이상 차이나는 대상만 출력
SELECT 부서ID
, MAX(연봉) AS 최대연봉
, MIN(연봉) AS 최소연봉
, MAX(연봉)-MIN(연봉) AS 연봉차이
FROM 직원
GROUP BY 부서ID
HAVING MAX(연봉)-MIN(연봉) >= 4500;
⑥ 전체 직원의 연봉의 평균값을 소수점 1자리까지 반올림하여 출력
연결연산자(||) 를 입력하여 출력되는 값 뒤에 '만원' 을 추가
SELECT ROUND(AVG(연봉), 1)||'만원' AS 평균연봉
FROM 직원;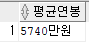
⑦ 직원 테이블에서 연도별로 입사한 직원의 수를 출력
연도별 입사한 직원 수를 출력, 연도를 기준으로 오름차순 정렬하여 출력
입사일시가 정해지지 않은(NULL) 대상은 출력하지 않음
SELECT TO_CHAR(입사일시, 'YYYY') AS 입사연도
, COUNT(입사일시) AS 명수
FROM 직원
WHERE 입사일시 IS NOT NULL
GROUP BY TO_CHAR(입사일시, 'YYYY')
ORDER BY TO_CHAR(입사일시, 'YYYY');
⑧ 직원 테이블의 직원ID , 패스워드 , 이름 , 성별 , 나이 컬럼을 기준으로 내림차순 정렬
나이 컬럼이 정해지지 않았다면 0 이 출력되도록 NULL 대체 함수를 적용한 다음에 정렬
SELECT 직원ID
, 패스워드
, 이름
, 성별
, NVL(나이, 0)
FROM 직원
ORDER BY 나이 DESC;
⑨ 직원 테이블의 모든 데이터를 출력
부서ID 를 기준으로 오름차순 정렬, 동일한 부서ID 내에서는 나이를 기준으로 내림차순 정렬
SELECT *
FROM 직원
ORDER BY 부서ID
, 나이 DESC ;
⑩ 직원테이블에서 20대 , 30대 , 40대 , 50대 연령대의 수를 출력
SELECT NVL2(FLOOR(나이/10)*10, FLOOR(나이/10)*10||'대', '미정') AS 연령대
, COUNT(*)||'명' AS 명수
FROM 직원
GROUP BY FLOOR(나이/10)*10
ORDER BY 연령대 ;
'Oracle SQL Developer' 카테고리의 다른 글
| SQL FROM, JOIN (0) | 2023.01.24 |
|---|---|
| SQL WHERE (1) | 2023.01.23 |
| SQL SELECT 연산, 내장형 함수 (0) | 2023.01.09 |
| SQL 기본 (0) | 2023.01.08 |
| DB 데이터 모델링(Data Modeling) (0) | 2023.01.05 |




댓글