머신러닝 기초 2
1. 머신러닝 과정
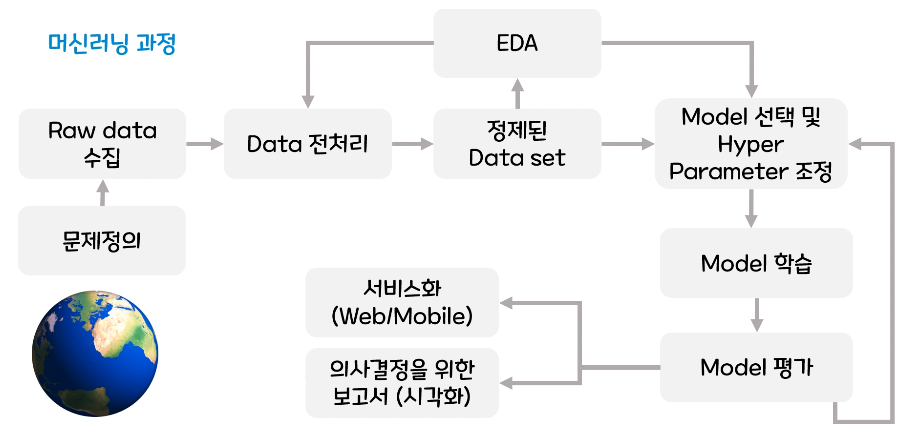
- ① Problem Identification (문제 정의)
비즈니스 목적 정의 모델을 어떻게 사용해 이익을 얻을 지 확인
현재 솔루션의 구성 파악
지도 vs 비지도 vs 강화, 분류 vs 회귀
(ex : 다음 학기 성적 점수 예측 → 회귀(직전 학기 성적, 알바 진행 여부, 연애 등))
(ex : 다음 학기 학점 예측 → 분류) - ② Data Collect (데이터 수집)
File (CSV, XML, JSON), Database, Web Crawler, IoT 센서를 통한 수집, Survey - ③ Data Preprocessing (데이터 전처리)
결측치, 이상치 처리
Feature Engineering (특성공학) : Scaling (단위변환)
Encoding (범주형 → 수치형)
Binning (수치형 → 범주형)
Transfrom (새로운 속성 추출) - ④ EDA (Exploratory Data Analysis, 탐색적 데이터 분석)
기술통계, 변수간 상관관계
시각화 : pandas, matplotlib, seaborn
Feature Selection (사용할 특성 선택) - ⑤ Model 선택, Hyper Parameter 조정
목적에 맞는 모델 선택 : KNN, SVM, Linear Regression, Ridge, Lasso, Decision Tree, Random forest 등
Hyper Parameter : model 성능을 개선하기 위해 사람이 직접 넣는 parameter
(ex: KNeighborsClassifier(n_neighbors=1) 에서 n_neighbors) - ⑥ Model Training (학습)
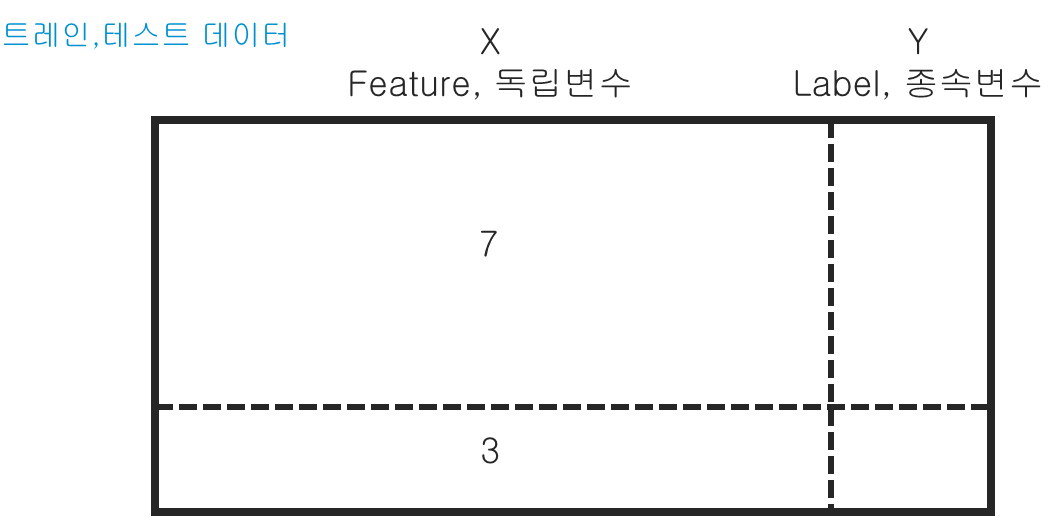
model.fit(X_train, y_train) : train 데이터와 test 데이터를 7:3 정도로 나눔
model.predict(X_test) - ⑦ Evaluation (평가)
분류 : accuracy (정확도), recall (재현율), precision (정밀도), f1score
회귀 : MSE(Mean Squared Error), RMSE(Root Mean Squared Error), R²(R Square)
※ train, test 데이터
▶ 예제
비만도 데이터 이용 학습
500명의 키와 몸무게, 비만도 라벨을 이용해 비만을 판단하는 모델 만들기
① 라이브러리 import
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings("ignore")
② 인덱스를 label 컬럼으로 bmi_500.csv 불러오기
# 인덱스를 Label 컬럼으로 bmi_500.csv 불러오기
data = pd.read_csv("./data/bmi_500.csv", index_col="Label")
data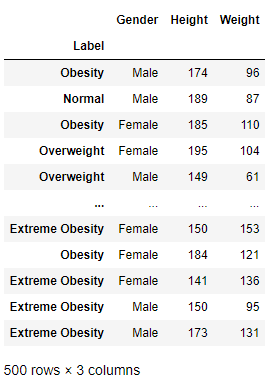
③ .info() : 데이터 프레임에 대한 정보를 간략하게 설명 (전체 행의 개수, 컬럼 정보, 결측치 여부 등)
# .info() : 데이터 프레임에 대한 정보를 간략하게 설명해주는 기능
# 전체 행의 개수, 컬럼 정보, 결측치 여부
data.info()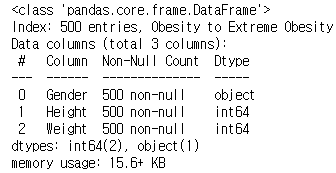
④ 데이터 전처리 : 학습용 데이터를 이용하기 때문에 이미 전처리 완료
⑤데이터 분석 (EDA, 탐색적 데이터 분석) : 기술 통계 확인, 시각화를 통해 데이터 분포 현황 알아보기
.describe() : 기술 통계 확인
.unique() : 고유값 확인
.value_counts() : 개수 카운트
d = data.loc['컬럼명']
plt.scatter(d['X축값'], d['Y축값'], c=color, label=label)
# 기술 통계 확인
data.describe()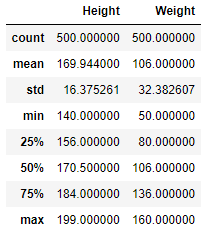
# Label 고유값 확인하기
data.index.unique()
# Extreme Obesity : 고도비만
# Obesity : 비만
# Overweight : 과체중
# Normal : 보통(정상)
# Weak : 저체중
# Extremely Weak : 심각한 저체중
# 레이블별 개수 카운트
data.index.value_counts()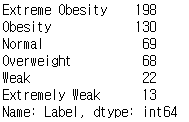
# bmi 레이블별 분포현황을 시각화 하기
d = data.loc['Obesity']
plt.scatter(d['Height'], d['Weight'], c='blue', label='obe')
plt.legend() # 범례
plt.show()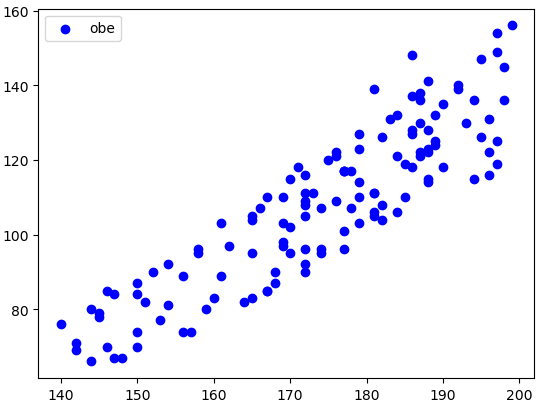
# 그래프 그리기 함수
def bmi_draw(label, color) :
d = data.loc[label]
plt.scatter(d['Height'], d['Weight'], c=color, label=label)bmi_draw('Extreme Obesity', 'red')
bmi_draw('Obesity', 'orange')
bmi_draw('Overweight', 'yellow')
bmi_draw('Normal', 'green')
bmi_draw('Weak', 'blue')
bmi_draw('Extremely Weak', 'purple')
plt.legend
plt.show()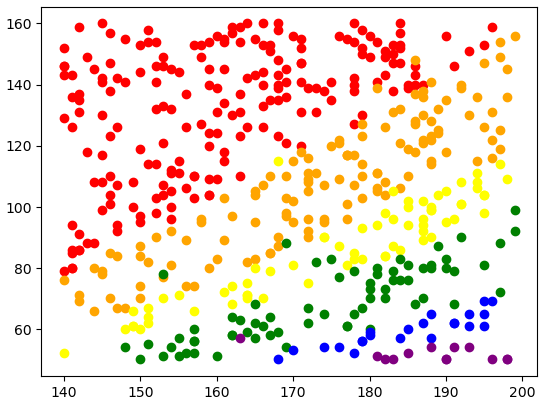
⑥ knn 모델 사용
knn_model = KNeighborsClassifier()X_train = data.iloc[:350,1:3]
y_train = data.index[:350]
X_test = data.iloc[350:,1:3]
y_test = data.index[350:]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
knn_model.fit(X_train, y_train)
pre = knn_model.predict(X_test)
accuracy_score(y_test, pre)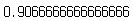
※ model.score(테스트 문제, 테스트 정답) : 모델 내부 자체에서 정확도 확인
# 모델 내부 자체에서 정확도를 확인하는 방법
# model.score(테스트 문제, 테스트 정답)
# 모델 내부에서 예측해서 실제 정답과 비교한 정확도를 출력
knn_model.score(X_test, y_test)
'Machine Learning' 카테고리의 다른 글
| 머신러닝 Decision Tree, 교차 검증, 특성 선택 (0) | 2023.03.20 |
|---|---|
| 머신러닝 분류 평가 지표 (0) | 2023.03.12 |
| 머신러닝 기초 3, KNN모델을 이용한 붓꽃 품종 분류 실습 (0) | 2023.03.12 |
| 머신러닝 기초 1, and/xor 연산 (1) | 2023.03.11 |
| 머신러닝 기초통계 (0) | 2023.03.11 |




댓글