머신러닝 기초 3, KNN모델을 이용한 붓꽃 품종 분류 실습
1. 머신러닝 일반화, 과대적합, 과소적합
- 모델의 신뢰도를 측정하고, 성능을 확인하기 위한 개념
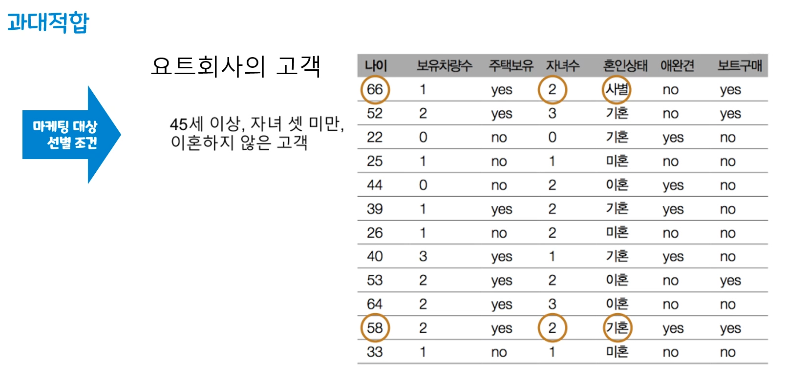
- 과대적합(Overfitting)
훈련 세트에 너무 맞추어져 있어 테스트 세트의 성능 저하
너무 상세하고 복잡한 모델링을 하여 과도하게 정확히 동작하는 모델 - 과소적합(Underfitting)
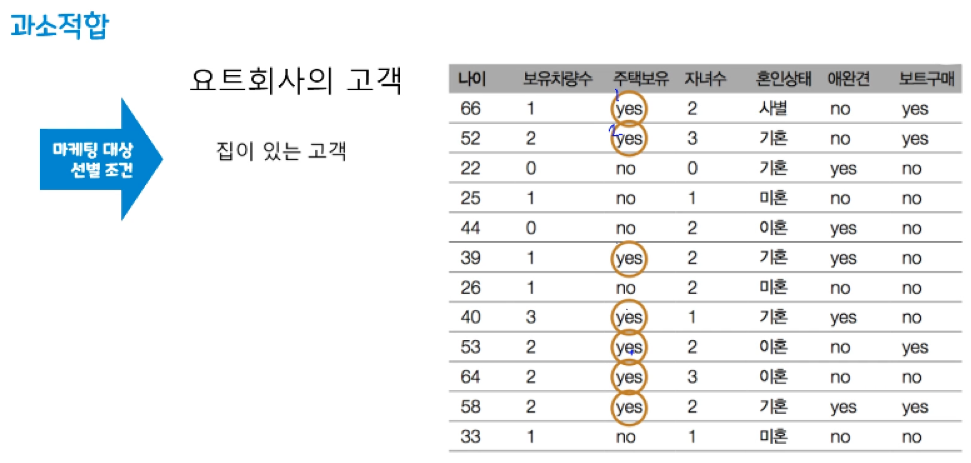
훈련 세트를 충분히 반영하지 못해 훈련 세트, 테스트 세트에서 모두 성능이 저하
모델링을 너무 간단하게 하여 성능이 제대로 나오지 않은 모델 - 일반화(Generalization)
훈련 세트로 학습한 모델이 테스트 데이터가 주어져도 정확한 예측을 기대 가능
(훈련 세트에서 테스트 세트로 일반화가 되었다고 함)
일반화 성능이 최대화 되는 모델을 찾는 것이 목표


2. 모델 복잡도

3. 모델 복잡도 해결
- 일반적으로 데이터 양이 많으면 일반화에 도움이 됨
- 주어진 훈련 데이터의 다양성이 보장되어야 함
- 다양한 데이터 포인트를 골고루 나타내기
- 편중된 데이터를 많이 모으는 것은 도움이 되지 않음
- 규제(Regularization)을 통해 모델 복잡도를 적정선으로 설정
4. KNN (K-Nearest Neighbors, K-최근접 이웃 알고리즘)
- 유유상종의 개념과 유사
- 새로운 데이터 포인트와 가장 가까운 훈련 데이터 세트의 데이터 포인트를 찾아 예측
- 분류와 회귀에 모두 사용 가능
- n_neighbors : 이웃의 수, metrics : 유클리디안 거리 방식


- k값에 따라 가까운 이웃의 수가 결정
k값이 작을수록 모델 복잡도가 상대적으로 증가 (noise 값에 민감)
k값이 커질수록 모델 복잡도가 낮아짐
(100개의 데이터를 학습, k를 100개로 설정 예측하면 빈도가 가장 많은 클래스 레이블로 분류 → 과소적합)
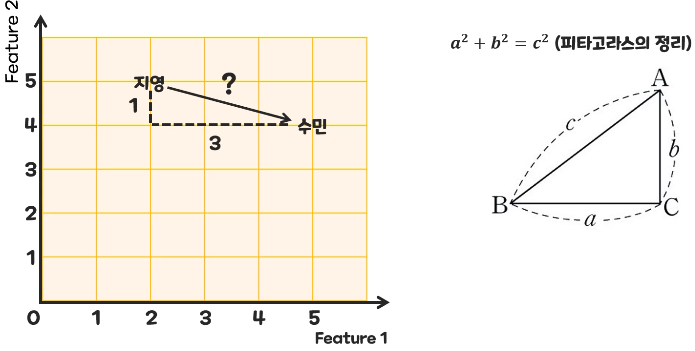
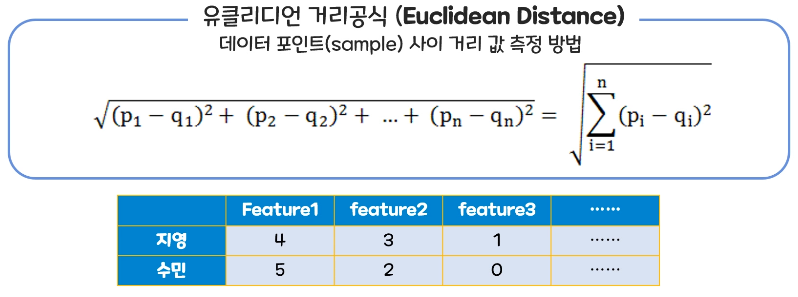
- KNN 거리 공식
2차원 : 피타고라스의 정리 이용
다차원 : 유클리디언 거리 공식 이용
- KNN 장단점
이해하기 매우 쉬운 모델
새로운 테스트 데이터 세트가 들어오면 훈련 세트와의 거리를 계산해 훈련 세트가 크면(특성, 샘플 수) 예측이 느려짐
수백개의 많은 특성을 가진 데이터 세트와 특성 값 대부분이 0인 희소(sparse)한 데이터 세트에는 잘 동작하지 않음
거리를 측정하기 때문에 같은 scale을 같도록 정규화 필요
▶ 예제
KNN모델을 이용한 붓꽃 품종 분류 실습
붓꽃 꽃잎의 길이와, 너비, 꽃받침의 길이와 너비 4가지 특성을 활용해 3가지 붓꽃 품종 분류
knn 모델의 이웃 숫자를 조절하여 하이퍼 파라미터 튜닝 결과를 확인하기
1. 붓꽃 데이터 준비
① 라이브러리 import
from sklearn.model_selection import train_test_split : 데이터를 랜덤으로 분할하는 라이브러리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split # 데이터 랜덤 분할 라이브러리
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings("ignore")
② 데이터 세트 확보 : sklearn에서 제공하는 학습용 붓꽃 데이터 사용
from sklearn.datasets import load_iris # 붓꽃 품종 데이터
iris_data = load_iris()
iris_data
③ 데이터 구조 확인
.keys() : 키 값 확인
data(필수) : 문제 데이터 (4가지 특성값이 들어있는 데이터)
target(필수) : 정답 데이터 (0, 1, 2)
feature_names(옵션) : 문제 데이터 특성 이름 (컬럼명)
target_names(옵션) : 붓꽃 품종의 실제 이름
DESCR(옵션) : Describe, 데이터 세트에 대한 간단한 설명
# 데이터 구조를 확인하기 위해 키 값 확인
iris_data.keys()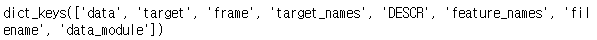
print(iris_data['DESCR'])
# 문제 데이터 확인
iris_data['data']# 정답 데이터 확인
iris_data['target']# target_names 확인
iris_data['target_names']# feature_names 확인
iris_data['feature_names']
# sepal length (cm) : 꽃받침 길이
# sepal width (cm) : 꽃받침 너비
# petal length (cm) : 꽃잎 길이
# petal width (cm) : 꽃잎 넓이
2. 데이터 세트 구성하기
① 분석 편의성을 위해 문제 데이터를 데이터 프레임화(컬럼명을 feature_names 지정)
# 분석의 편의성을 위해 문제 데이터를 데이터 프레임화 해주기
# iris_data['data']를 데이터 프레임화
# 컬럼명 지정 -> feature_names로 지정해주기
df = pd.DataFrame(iris_data['data'], columns=iris_data['feature_names'])
df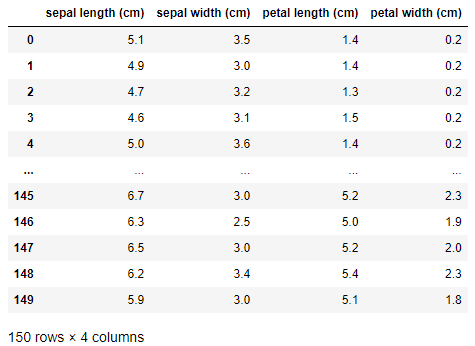
② 결측치 확인
.info()
# 결측치 확인 : 결측치가 없기 때문에 별도로 채워줄 필요가 없음
df.info()
③ 정답 데이터의 분할 정도 확인
정답 데이터를 7:3으로 분할하면 0과 1만 존재하는 문제 데이터와 2만 존재하는 평가 데이터로 분할
→ 데이터가 골고루 섞여서 분할이 되야 함
from sklearn.model_selection import train_test_split
train_test_split(문제데이터, 정답데이터, test_size=, random_state=)
다중 변수 입력과 train_test_split을 이용해 분할
변수 설정 순서 유의 : X_train, X_test, y_train, y_test (중요)
test_size : 평가용 테스트 사이즈 비율
random_state = 랜덤 시드 고정값
# 다중 변수 입력과 train_test_split을 이용해 분할
# train_test_split(문제데이터, 정답데이터, test_size=, random_state=)
# 변수 설정 순서 유의 : X_train, X_test, y_train, y_test (중요)
# test_size : 평가용 테스트 사이즈 비율
# random_state = 랜덤 시드 고정값
X_train, X_test, y_train, y_test = train_test_split(df, y,
test_size=0.3,
random_state=10)print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
④ 데이터가 균등하게 분할되었는지 확인
np.bincount()
# y 데이터가 균등하게 분할되었는지 확인
# numpy의 .bincount() 이용
np.bincount(y_train)
3. 탐색적 데이터 분석
① 산점도 행렬 이용
한꺼번에 변수간 관계를 편하게 표현해주는 방법
(X축, Y축이 같을 경우에는 도수분포 출력)
pandas.plotting.scatter_matrix()
# 산점도 행렬 : 한꺼번에 변수간 관계를 편하게 표현해주는 방법
pd.plotting.scatter_matrix(df,
figsize = (10, 10),
c = y,
alpha = 0.9)
plt.show()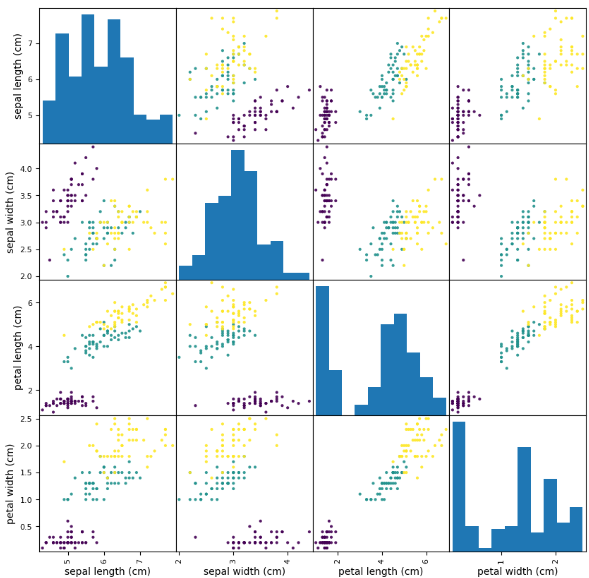
4. 모델링
# 모델 객체 생성 (사용하기 위해 변수 저장)
knn_model = KNeighborsClassifier()
# 모델 학습
knn_model.fit(X_train, y_train)
# 모델 예측
pre = knn_model.predict(X_test)
print("- 테스트 세트 전체를 이용한 예측 결과값 \n", pre)
print("- 예상되는 품종 : ", iris_data['target_names'][pre]) #pre가 인덱스번호처럼 동작
# 모델 평가 (정확도 예측)
accuracy_score(y_test, pre)
5. 하이퍼 파라미터 조정
① n_neighbors값에 따라 변화하는 정확도를 test_list, train_list 저장
test_list = []
train_list = []
# 1부터 50까지의 값을 neighbors_setting에 저장
neighbors_setting = range(1,51)
# 반복문을 이용해 이웃값을 살펴보고, 값을 확인
for k in neighbors_setting :
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train, y_train)
test_score = knn_clf.score(X_test, y_test)
test_list.append(test_score)
train_score = knn_clf.score(X_train, y_train)
train_list.append(train_score)
② 하이퍼 파라미터 튜닝 결과 시각화
# 하이퍼 파라미터 튜닝의 결과 시각화
plt.figure(figsize = (10, 4))
plt.plot(range(1,51), train_list, label='train_acc', marker="o")
plt.plot(range(1,51), test_list, label='test_acc', marker="d")
plt.legend() # 범례
plt.grid() # 격자 눈금
plt.xticks(range(1,51,2)) # X축 축척 조절
plt.xlabel('n_neighbors') # X축 라벨
plt.ylabel('accuracy_score') # Y축 라벨
plt.show()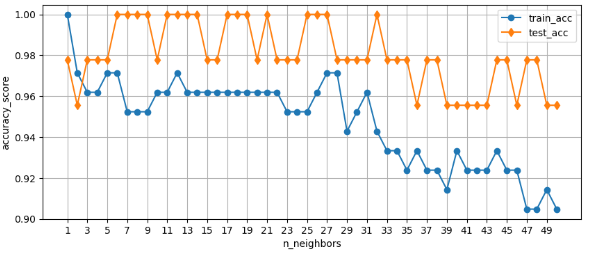
결과) n_neighbors = 5 일 때의 값이 train과 test가 비슷하게 나옴
'Machine Learning' 카테고리의 다른 글
| 머신러닝 Decision Tree, 교차 검증, 특성 선택 (0) | 2023.03.20 |
|---|---|
| 머신러닝 분류 평가 지표 (0) | 2023.03.12 |
| 머신러닝 기초 2, 비만도 데이터 이용 학습 (0) | 2023.03.11 |
| 머신러닝 기초 1, and/xor 연산 (1) | 2023.03.11 |
| 머신러닝 기초통계 (0) | 2023.03.11 |




댓글