머신러닝 앙상블(Ensemble)
앙상블 : 여러 개의 모델이 예측한 값을 결합하여 정확한 최종 예측을 도출하는 기법
앙상블을 사용하는 이유
- 단일 모델에 비해 높은 성능과 신뢰성을 얻음
- 데이터의 양이 적은 것에 대비하여 충분한 학습 효과 가능
앙상블 방법
- 보팅(Voting)
여러 개의 다른 종류의 모델이 예측한 결과를 투표 혹은 평균을 통해 최종 선정 - 베깅(Bagging)
여러 개의 같은 종류의 모델이 예측한 결과를 투표 혹은 평균을 통해 최종 선정 - 부스팅(Boosting)
여러 개의 같은 종류의 모델이 순차적으로 학습-예측하여 오류를 개선하는 방식
1. 보팅(Voting)
- 하드 보팅(Hard voting) : 다수결
- 소프트 보팅(Soft voting) : 각 확률의 평균
(일반적으로 소프트 보팅의 예측 성능이 상대적으로 우수하여 주로 사용)

- 회귀 모델은 각 모델들이 예측한 수치값의 평균을 통해 최종 예측
2. 베깅(Bagging)
- 보팅과 베깅의 공통점 : 여러 개의 모델이 투표 혹은 평균을 통해 최종 예측 결과를 선정
- 보팅과 베깅의 차이점
① Voting : 서로 다른 모델을 결합
② Begging : 같은 종류의 모델을 결합 (데이터 샘플링을 다르게 하거나, 중첩을 허용) - 베깅의 대표적 모델 : 랜덤 포레스트(트리모델 기반)
랜덤 포레스트 (Random Forest)
- 결정 트리 모델 이용
(직관적이어서 결과를 쉽게 이해하지만, max_depth가 커질수록 과대적합이 되기 쉬움) - 다수의 의사결정트리의 의견이 통합 불가 → 다수결 원칙 적용 → 앙상블
- 장점
결정 트리 모델처럼 쉽고 직관적
실제 값에 대한 추정값 오차 평균화, 분산 감소, 과대적합 감소
부스팅 방식에 비해 빠른 수행 속도 - 단점
모델 튜닝을 위한 시간이 많이 필요 (하이퍼 파라미터의 종류가 많음)
큰 데이터 세트에도 잘 동작하지만 트리 개수가 많아질수록 시간이 오래 걸림
랜덤 포레스트 주요 매개변수(Hyperparameter)
- RandomForestClassifier(n_estimatiors, max_features, random_state)
n_estimatiors : 트리의 개수
max_features : 최대 선택할 특성 수
random_state : 랜덤 시드
※ max_features 값의 변화
int : 특성 수
float : 전체 특성의 백분율
① max_features 값을 크게 하기
tree들은 같은 특성을 고려하므로 tree들이 매우 비슷해지고 가장 두드러진 특성을 이용해 데이터에 잘 맞음
② max_features를 낮추기
tree들은 많이 달라지고 각 tree는 데이터에 맞추기 위해 tree의 깊이가 깊어짐
3. 부스팅(Boosting)
- 여러 개의 모델이 순차적으로 학습-예측하며 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해 나가면서 학습
순차적으로 진행되기 때문에 속도가 떨어지나, 오차가 점점 수정되어 정확도를 올리기 좋음 - 결정 트리 모형을 베이스로 사용
※ 베깅과 부스팅
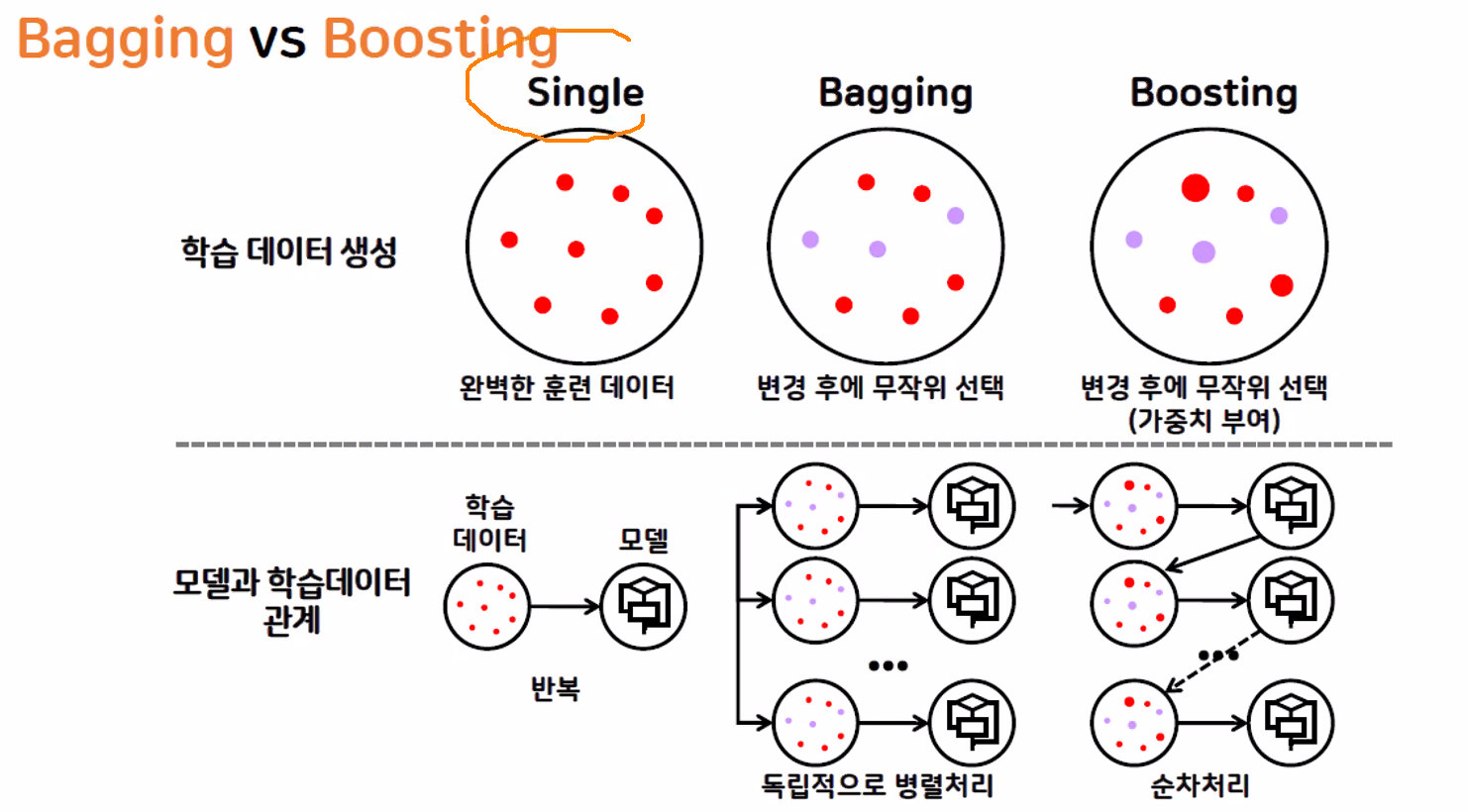
| 구분 | 베깅(Baggin) | 부스팅(Boosting) |
| 특징 | 같은 종류의 모델이 투표를 통해 최종 예측 결과 도출 (데이터 샘플을 다르게 가져감) |
순차 학습 + 예측 (이전 모델의 오류를 고려) |
| 목적 | 일반적으로 좋은 모델을 목표 과대적합 방지 (편향 학습 방지) |
맞추기 어려운 문제를 해결 과소적합 방지 (학습 부족 방지) |
| 적합 상황 | 데이터 값들의 편차가 클 경우 | 학습 정확도가 낮거나 오차가 클 경우 |
| 대표 모델 | Random Forest | Ada Boosting, Gradient Boosting, XG boosting, Light GBM |
| 데이터 선택 | 무작위 선택 | 무작위 선택 (오류 데이터 가중치 적용) |
에이다 부스팅 (Ada Boosting; Adaptive Boosting)
- 랜덤 포레스트처럼 의사결정 트리 기반 모델 → 각각의 트리들이 독립적으로 존재하지 않음
- 학습과 예측을 진행할수록 데이터들의 가중치가 달라짐
잘못 분류된 데이터에 가중치를 높이고, 잘 분류된 데이터는 가중치를 낮춤 - 각 트리(stump)들의 가중치를 다르게 설정
예측률이 높은 트리는 가중치를 높이고, 낮은 트리는 가중치를 낮춤
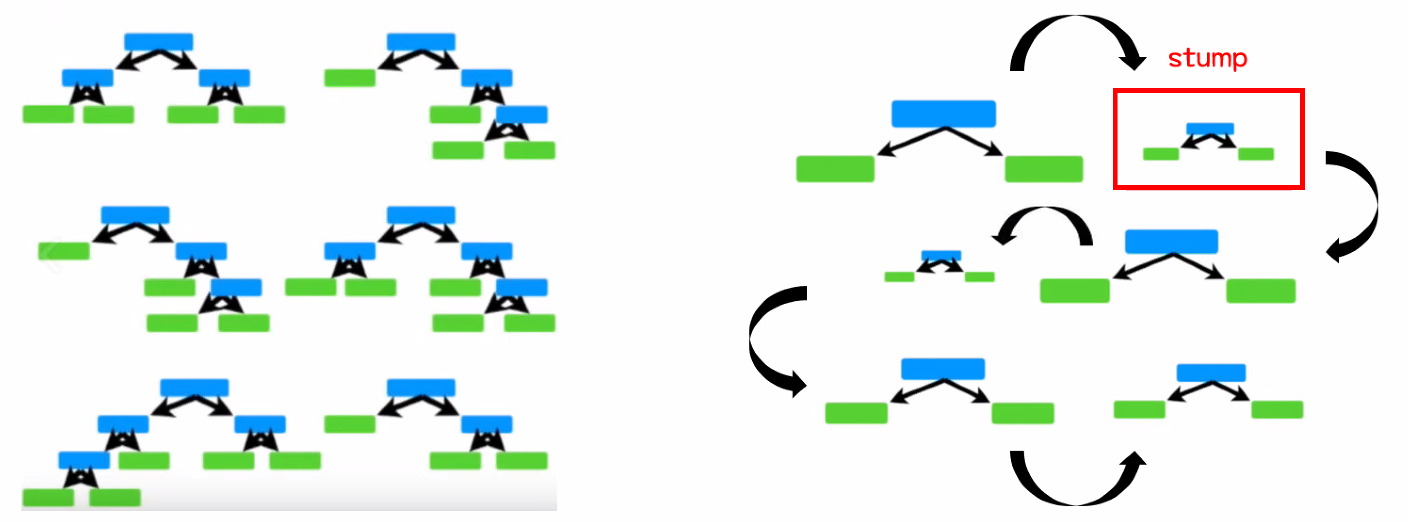
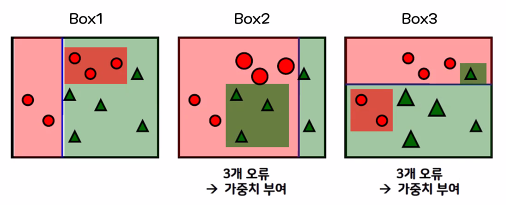
- 에이다 부스팅 동작 순서
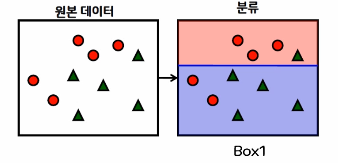
①첫 번째 의사 결정 트리를 생성
위쪽 빨간원이 3개 있는 곳을 대충 분류 → 2개의 빨간 원과 1개의 녹색 세모가 잘못 구분
② 잘못된 2개의 빨간 원과 1개의 녹색 세모에 높은 가중치를 부여하고, 맞은 빨간원 3개와 녹색 세모 4개는 낮은 가중치를 부여
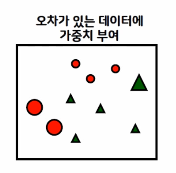
③ 가중치를 부여한 상태에서 다시 분류
잘못된 3개의 빨간원에 높은 가중치를 부여하고, 맞은 5개의 녹색 세모는 낮은 가중치를 부여
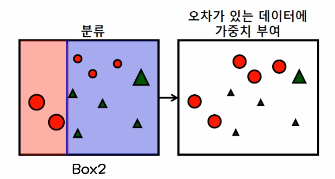
④ 가중치를 부여한 상태에서 다시 재분류
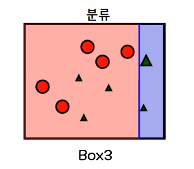
⑤ 진행한 분류들을 결합

그래디언트 부스팅 (Gradient Boosting Machine)
- AdaBoost와 기본 개념은 동일
- 가중치를 계산하는 방식에서 경사하강법을 사용해 최적의 가중치(파라미터)를 찾아냄
- 학습 속도가 느림 (부스팅의 일반적 단점)
- 데이터 특성의 스케일 조정 불필요 (트리 기반 모델의 특성)
- 주요 매개변수(Hyperparameter)
GradientBoostingClassifier(n_estimators, learning_rate, max_depth, random_state)
n_estimators : 트리의 개수
learning_rate : 학습률 (높을수록 오차를 많이 보정)
max_depth : 트리의 깊이
random_state : 선택 데이터 시드
XG 부스팅 (eXtreme Gradient Boosting)
- GBM 단점인 느리고, 과대적합 문제 → Early Stopping 제공, 과대적합 방지를 위한 규제를 포함
(Early Stopping : 일정 횟수를 시행하여도 정확도가 올라가지 않으면, 멈추어서 과대적합 방지) - 병렬로 빠른 학습 가능
- 주요 매개변수(Hyperparameter)
XGBClassifier(n_estimators, learning_rate, max_depth, random_state)
n_estimators : 트리의 개수
learning_rate : 학습률 (높을수록 오차를 많이 보정)
max_depth : 트리의 깊이
random_state : 선택 데이터 시드
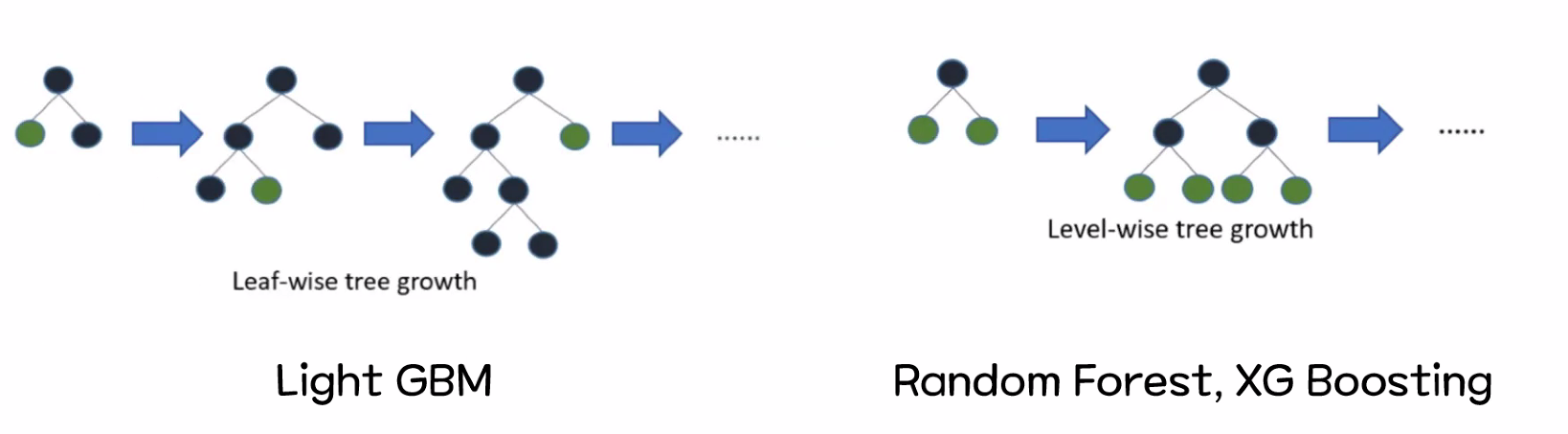
Light GBM
- XG Boosting에 비해 가벼워 속도가 빠른 모델 (Low memory)
- Leaf-wise(수직방향, 비대칭, 한쪽 방향을 먼저 끝까지 탐색)로 트리를 성장 → 속도 상승
Level-wise(수평방향, 대칭)보다 오류가 더 적음 → 정확도 상승 - 대량(1만개 이상)의 데이터를 병렬로 빠르게 학습 가능 (Low Memory, GPU 활용 가능)
XG Boosting 대비 2~10배의 속도 (동일 파라미터 설정 시)
소량 데이터에서는 제대로 동작하지 않음 (과대적합 위험, 1만개 이상 데이터 필요) - 예측 속도(Leaf-wise 트리 장점)가 빠르지만, XG Boosting(Level-wise)에 비해 과적합에 민감
4. Grid Search
- 하이퍼파라미터를 설정하는 것은 모델링에서 매우 중요한 일
- 관계있는 하이퍼파라미터들을 대상으로 가능한 모든 조합을 시도
- 주요 매개변수(scikit-learn)
GridSearchCV(모델, 모델 파라미터 목록, cv)
'Machine Learning' 카테고리의 다른 글
| 머신러닝 로지스틱 회귀(Logistic Regression) (0) | 2023.03.24 |
|---|---|
| 머신러닝 선형 회귀 (0) | 2023.03.24 |
| 머신러닝 Decision Tree, 교차 검증, 특성 선택 (0) | 2023.03.20 |
| 머신러닝 분류 평가 지표 (0) | 2023.03.12 |
| 머신러닝 기초 3, KNN모델을 이용한 붓꽃 품종 분류 실습 (0) | 2023.03.12 |




댓글