파이썬 라이브러리 Numpy (Python Library Numpy)
※ import numpy as np : numpy 모듈을 import하고 np라는 별칭으로 부르겠다. ( np 사용 권장 )
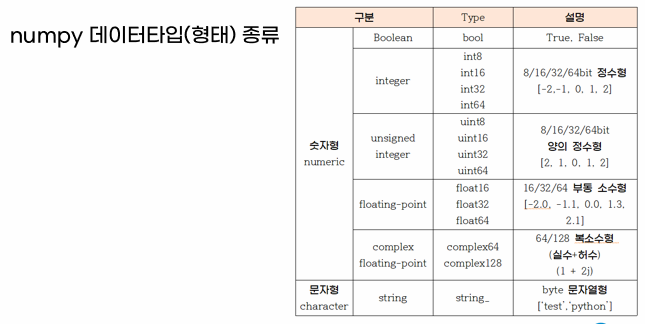
다차원 배열 제공
- ndarray(number of dimension array) 클래스가 지원하고 있음
- 동일한 자료형을 가지는 값들이 배열 형태로 존재
- n차원의 형태로 구성 가능
- 데이터에 접근을 최적화하기 위해 index(색인)를 부여
1. 배열 생성
① 1차원 배열 생성
- 배열 생성 함수 : np.array()
lst1 = [1, 2, 3, 4, 5] # 리스트
arr = np.array(lst1) # 배열을 생성하는 함수 np.array()
arr # 배열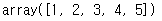
② 2차원 배열 생성
arr2 = np.array([[1,2,3],[4,5,6]])
arr2
③ 타입을 지정하여 배열 생성 : np.array(배열데이터, dtype = np.데이터타입)
arr_dtype = np.array([1.2, 2.3, 3.4], dtype = np.int64)
arr_dtype
④ 생성된 배열의 타입 변경하기 : 배열명.astype(np.데이터타입)
arr_dtype = np.array([1.2, 2.3, 3.4], dtype = np.int64)
arr_type = arr_dtype.astype(np.float64)
arr_type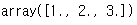
arr_type.dtype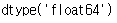
⑤ 특정한 값으로 배열 생성하기
- np.zeros((행, 열))
arr_zeros = np.zeros((3, 4))
arr_zeros
- np.ones((행, 열))
arr_ones = np.ones((4,5))
arr_ones
- np.fulls((행, 열), 특정숫자)
arr_full = np.full((3,3), 7)
arr_full
⑥ 연속된 특정 숫자로 배열 생성
- for문 range함수를 이용해 리스트를 만들고, 리스트를 담은 배열 생성
lst1 = []
for i in range(1,51) :
lst1.append(i)
arr_l = np.array(lst1)
arr_l
- np.arange(시작, 끝, 증감값) : 1차원 배열만 생성
range_arr = np.arange(1,51)
range_arr
- np.arange(시작, 끝, 증감값).reshpae(행,열) : 2차원 배열 생성
range_arr2 = np.arange(1,51).reshape(5,10)
range_arr2
- arr_ran = np.random.rand(행,열) : 0~1까지 랜덤 수를 행, 열을 가지는 배열 형태로 생성
arr_ran = np.random.rand(2,3)
arr_ran
arr_randint = np.random.randint(1,51, size=(5,10))
arr_randint
2. 배열 변수
- 배열의 크기 확인 : shape
- 배열의 차원 확인 : ndim
- 배열 전체의 요소 개수 확인 : size
- 배열 데이터 타입 확인 : dtype
① shape : 배열의 크기 확인
arr2 = np.array([[1,2,3],[4,5,6]])
print(arr2)
arr2.shape
② ndim : 배열의 차원 확인
arr2 = np.array([[1,2,3],[4,5,6]])
print(arr2)
print(arr2.ndim,'차원')
③ size : 배열의 전체 요소 개수 확인
lst1 = [1, 2, 3, 4, 5]
arr = np.array(lst1)
print(arr)
print(arr.size)
④ dtype : 배열의 타입 확인
arr_float = np.array([1.2, 3.4, 5.6])
print(arr_float)
print(arr_float.dtype)
3. 배열 연산
배열 요소별 연산
arr3 = np.arange(2,10,2)
print(arr3)
print(arr3/2) # 차원이 다른 연산 가능 Broadcasting
print(arr3+5)
print(arr3+arr3) # 배열끼리도 연산 가능
4. 데이터 접근 (indexing & slicing)
① 1차원 배열 접근
arr5 = np.arange(1,11)
print(arr5)
print(arr5[1])
print(arr5[2:6])
print(arr5[[0,4,5]]) # 여러가지 데이터를 동시에 인덱싱 가능
② 2차원 배열 접근
※ np.arange().reshape(행, 열) : 1차원 배열을 2차원 행, 열 배열로 생성
arr6 = np.arange(1,51).reshape(5,10)
print(arr6)
print(arr6[4,2]) # 2차원 배열 인덱싱
print(arr6[:,2]) # 2차원 배열 슬라이싱
print(arr6[2:,5:]) # 2차원 배열 슬라이싱
arr2 = np.arange(30).reshape(5,6)
print(arr2)
print(arr2[2,2])
print(arr2[3,3])
print(arr2[[2,3],[2,3]]) # 2차원 배열에서 여러 값을 한번에 인덱싱하기
arr6 = np.arange(1,51).reshape(5,10)
print(arr6)
print(arr6[1,[4,5,6]]) # 행 하나의 여러열 값 인덱싱
print(arr6[3, ::3]) # 행 하나의 여러열 값 슬라이싱
5. boolean 인덱싱
- 논리 연산자를 활용하여 True, False 결과 출력
- True값에 해당하는 데이터만 접근
- 특정 기준에 의해 접근하는 방식
※ 랜덤 값을 생성할 때 seed값을 주기 : seed값이 같으면 같은 랜덤 숫자 생성
np.random.seed(숫자)
▶ 연습
seed값을 4로 50~100까지 8개의 랜덤 값을 생성하고 score라는 1차원 배열을 생성하기
boolean인덱싱을 이용해 점수가 70이상인 값의 수를 구하기
np.random.seed(4)
score = np.array(np.random.randint(50,100, size=8))
print(score)
print(score[score>=70].size)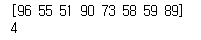
▶ 연습
height_weight.txt 데이터를 불러오고, bmi 지수 구하기
(bmi 지수 = 몸무게/키(m)**2)
과체중 bmi 지수 23<= bmi <=25 데이터 개수 구하기
※ numpy 데이터 불러오기 (delimiter 데이터 구분자)
np.loadtxt('주소경로', delimiter=' ')
※ 비트연산자 &(and), |(or)
data = np.loadtxt('./data/height_weight.txt', delimiter=',')
data
bmi = data[1]/(data[0]*0.01)**2
bmi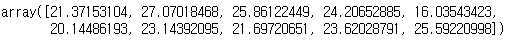
bmi[(bmi>=23)&(bmi<=25)].size
6. 데이터 수정하기
▶ 연습
2차원 배열 arr6의 1,3,5,7,9열 데이터를 모두 1로 바꾸기
arr6 = np.arange(1,51).reshape(5,10)
arr6arr6[:,::2] = 1
arr6
7. numpy 유용한 함수

arr7 = np.arange(1,30)
arr7
① sum()
print(arr7.sum())
print(np.sum(arr7))
② mean()
print(arr7.mean())
print(np.mean(arr7))
③ sqrt()
print(np.sqrt(arr7))
④ abs()
arr8 = np.array([-1,-2,-3,4,5,6])
print(arr8)
print(np.abs(arr8))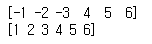
'Python' 카테고리의 다른 글
| 파이썬 라이브러리 Matplotlib(Python Library Matplotlib) (0) | 2023.01.15 |
|---|---|
| 파이썬 라이브러리 Pandas (Python Library Pandas) (0) | 2023.01.15 |
| 파이썬 함수(Python Function) (0) | 2023.01.10 |
| 파이썬 딕셔너리(Python Dictionary) (0) | 2023.01.08 |
| 파이썬 반복문(Python Loop) (0) | 2023.01.07 |




댓글