파이썬 라이브러리 Pandas(Python Library Pandas)
Pandas 공식 사이트 : https://pandas.pydata.org/
pandas - Python Data Analysis Library
pandas pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language. Install pandas now!
pandas.pydata.org
※ import pandas as pd : pandas 모듈을 import하고 pd라는 별칭으로 부르겠다. ( pd 사용 권장 )
- 1차원 배열 : Series, 인덱스(index) + 값(value)
- 2차원 배열 : DataFrame, 행과 열을 가지는 표와 같은 형태이며 서로 다른 자료형 저장 가능
1. Pandas 객체 생성 : Series, DataFrame
① 1차원 Series 데이터 생성 : pd.Series()
- list 이용
# 도시별 인구 수를 나타내는 Series 생성
population = pd.Series([9602000, 3344000, 1488000, 2419000])
population
- Series 데이터의 인덱스를 지정하여 생성 : pd.Series([값], index=[인덱스이름]) :
population = pd.Series([9602000, 3344000, 1488000, 2419000], index=['서울','부산','광주','대구'])
population
- 딕셔너리를 이용하여 Series 생성하기 : pd.Series({index:value, index:value, index:value})
area = pd.Series({'서울':605.2, '부산':770.1,'광주':501.1,'대구':883.5})
area
② Series 데이터 속성 확인
- index를 확인하고 싶을 때 : Series명.index (파이썬에서 데이터타입이 object면 그냥 문자열이라고 생각하기)
- value를 확인하고 싶을 때 : Series명.values (출력 결과는 numpy 배열 형태)
- 데이터 타입 확인 : Series명.dtype
population = pd.Series([9602000, 3344000, 1488000, 2419000], index=['서울','부산','광주','대구'])
population
population.values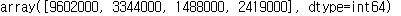
population.index
population.dtype
③ Series 이름 지정
- Series의 이름은 DataFrame의 컬럼명이 된다.
- Series명.name = 원하는이름
- Series명.index.name = 원하는인덱스이름
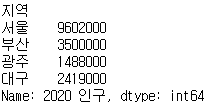
population = pd.Series([9602000, 3344000, 1488000, 2419000], index=['서울','부산','광주','대구'])
population
population.name = '2020 인구'
population
population.index.name = '도시'
population
④ Series 데이터 추가, 수정, 삭제
- 추가 : 없는 인덱스(키) 값을 불러주고 값을 입력 (딕셔너리 데이터 추가와 비슷)
# '전주' : 1400000
population['전주'] = 1400000
population
- 수정 : 인덱스 위치에 접근해서 값을 대입
# 부산 데이터에 접근해서 3500000으로 변경하기
population['부산'] = 3500000
# 인덱스 이름을 '지역'으로 변경하기
population.index.name = '지역'
- 삭제 : drop()
※ drop()을 사용하면 실행된 셀 내에서만 삭제되고 다른 셀에서 호출하면 데이터가 아직 존재한다.
데이터를 다른 셀에서도 삭제하려면 drop()의 속성값 inplace를 True로 바꿔주거나 drop결과를 다시 변수에 담는다.
population.drop('전주', inplace=True)
population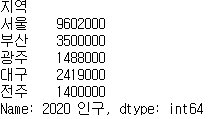
⑤ Series 병합 : pd.concat([Series1, Series2], axis=숫자)
- 1차원을 연결하여 2차원으로 변환 가능
- Series의 이름이 DataFrame의 컬럼명이 됨
- axis = 0 → row 방향으로 연결
- axis = 1 → column방향으로 연결
population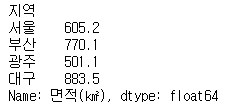
area
# axis = 0 (기본값)으로 row방향으로 붙이기
df = pd.concat([population, area], axis=0)
df
# axis = 1 으로 column 방향으로 붙이기
df = pd.concat([population, area], axis=1)
df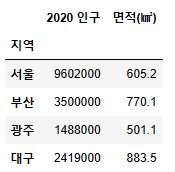
⑥ 2차원 DataFrame 생성 : pd.DataFrame()
- list 이용
data = [[1488000, 501.1], [2419000, 883.5], [1400000, 883.5], [2951000, 1065.2]]
data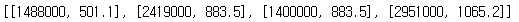
df = pd.DataFrame(data)
df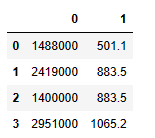
- 인덱스, 컬럼명을 설정해서 만들기
df2 = pd.DataFrame(data, index=['광주', '대구', '전주', '인천'], columns=['2022 인구', '면적(㎢)'])
df2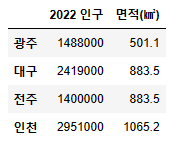
- 딕셔너리를 이용해 DataFrame 생성
data = {'2022 인구' : [1488000,2419000,1400000,2951000], '면적(㎢)' : [501.1,883.5,883.5,1065.2]}
df3 = pd.DataFrame(data, index=['광주','대구','전주','인천'])
df3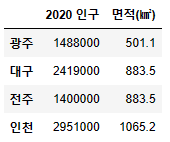
data = {'홍길동' : [175.3, 66.2, 27.0], '김사또' : [180.2, 78.9, 49.0], '임꺽정' : [178.6, 55.1, 35.0]}
df4 = pd.DataFrame(data, index=['키', '몸무게', '나이'])
df4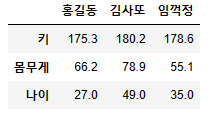
※ 행과 열을 전환하는 키워드 : .T
T(전치,Transpose)
data = {'홍길동' : [175.3, 66.2, 27.0], '김사또' : [180.2, 78.9, 49.0], '임꺽정' : [178.6, 55.1, 35.0]}
df4 = pd.DataFrame(data, index=['키', '몸무게', '나이'])
df4
df5 = df4.T
df5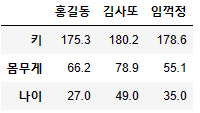
2. Pandas 데이터 접근하기 (인덱싱, 슬라이싱)
① Series 인덱싱, 슬라이싱
- Series 인덱싱
std1 = pd.Series({'java' : 95, 'python' : 100, 'db':85, 'html/css':75})
std1
# 자바 데이터에 접근
print(std1['java'])
print(std1[0])
# 데이터 여러개에 한번에 접근
print(std1[['java','python']])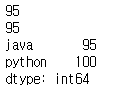
- Series 슬라이싱
std1['python':'db'] # 문자열로 접근할 때는 뒷값이 포함
std1[1:3] # 인덱스번호로 접근할 때는 뒷값이 포함 안됨 뒷값 + 1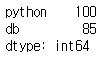
※ print()와 display()의 차이
print(std1['java':'python'])
print(std1[:'python'])
print(std1[0:2])
print(std1[:2])
display(std1['java':'python'])
display(std1[:'python'])
display(std1[0:2])
display(std1[:2])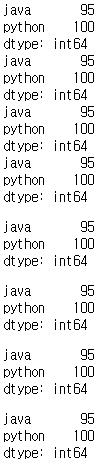
- Series boolean 인덱싱
# 데이터 안에서 85점 이상인 과목 확인
std1[std1 >= 85]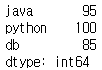
# 85점 이상인 과목만 가져오고 싶을 때
std1[std1>=85].index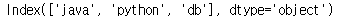
# 85점 이상 95점 미만인 과목 접근하기 (두 개의 조건을 연결~비트연산자 &, |)
std1[(std1>=85)&(std1<=95)]
② DataFrame 인덱싱, 슬라이싱
df_std1= pd.DataFrame({'java' : [95, 85, 80], 'python' : [100, 95, 90], 'db' : [85, 90, 100], 'html/css' : [75, 80, 95]}, index=['재석','명수', '홍철'])
df_std1
# python 성적 데이터 접근
df_std1['python'] # 1차원 Series 형태
# 2차원에서 [] 열고 값을 입력하면 컬럼이라고 인식
# 컬럼에 대한 인덱싱을 수행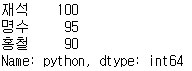
df_std1[['python']]
# 2차원 DataFrame 형태, 하나의 컬럼이지만 [[]] 표현하면 가능
# [[ ]] ==> row와 column 가져오므로 괄호 2개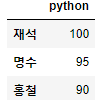
# row 슬라이싱
df_std1['재석':'홍철']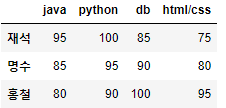
df_std1[1:3]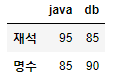
# 컬럼 인덱싱으로 여러개의 컬럼을 가져오기
df_std1[['java','db']]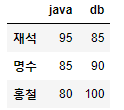
- loc, iloc 인덱서 : Pandas에서 특정 row, column에 접근할 때 사용
| loc 인덱서(location) 문자열 기반 데이터 접근, 실제 인덱스 값을 사용 |
|
| 행 접근 | df.loc[행] df.loc[시작행:끝행] df.loc[[행1,행2,행3,...]] |
| 열 접근 | df.loc[:,열] df.loc[:,시작열:끝열] df.loc[[:,열1,열2,열3,...]] |
| iloc 인덱서(int location) 인덱스 번호를 기반으로 데이터 접근, 눈에 보이지 않는 인덱스에도 접근 |
|
| 행 접근 | df.iloc[행인덱스] df.iloc[시작행인덱스:끝행인덱스] df.iloc[행인덱스,행인덱스,행인덱스,...] |
| 열 접근 | df.iloc[:,열인덱스] df.iloc[:,시작열인덱스:끝열인덱스] df.iloc[:,[열인덱스,열인덱스,열인덱스,...]] |
| loc,iloc를 이용해 원하는 행, 열에 동시 접근 | |
| loc 인덱서 | 배열명.loc[행,열] |
| iloc 인덱서 | 배열명.iloc[행번호,열번호] |
# python에서 html/css까지 모든 row 데이터 접근
display(df_std1.loc[:,'python':'html/css']) # loc 컬럼 슬라이싱
display(df_std1.loc[:,['python','db','html/css']]) # loc 컬럼 여러개 가져오기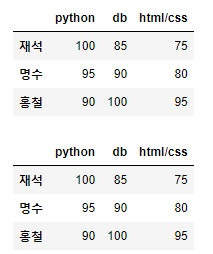
# java에서 db까지 모든 row 데이터 접근
display(df_std1.iloc[:,:3]) # iloc 컬럼 슬라이싱
display(df_std1.iloc[:,[0,1,2]]) # iloc 컬럼 여러개 가져오기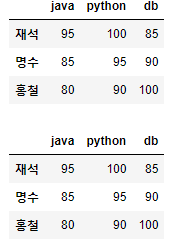
# python에서 html/css까지 모든 row 데이터 접근
display(df_std1[['python','db','html/css']]) # 컬럼 인덱싱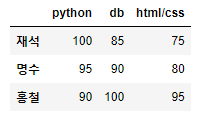
※ row 데이터 순서를 바꿔서 출력하기
# 명수, 재석 데이터 순으로 접근하기
df_std1.loc[['명수','재석']]
df_std1.iloc[[1,0]]
df_std1.iloc[1::-1]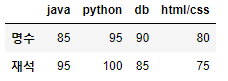
③ DataFrame boolean 인덱싱
df_std1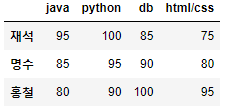
# python의 성적이 95점 이상인 사람의 수는 몇 명일까?
df_std1[df_std1['python']>=95].shape[0]
# boolean 인덱싱을 이용해 95점 이상 데이터에 접근하고 shpae를 사용해 row값을 가져옴
len(df_std1[df_std1['python']>=95].index)
# index만을 가져오고 len()을 이용해 길이 측정
# html/css의 성적이 80점 이상, 90점 미만인 사람의 수는 몇 명일까?
df_std1[(df_std1['html/css']>=80)&(df_std1['html/css']<90)].shape[0]
len(df_std1[(df_std1['html/css']>=80)&(df_std1['html/css']<90)].index)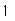
#'java' 85점 이상인 사람의 'html/css'점수 출력해보기
df_std1[df_std1.loc[:,'java']>=85]['html/css']
df_std1[df_std1.loc[:,'java']>=85].loc[:,'html/css']
df_std1[df_std1.loc[:,'java']>=85].iloc[:,-1]
df_std1.loc[df_std1['java']>=85,'html/css']
※ boolean 인덱싱은 loc 인덱서만 가능, iloc 인덱서는 불가능
# boolean 인덱싱은 loc만 가능, iloc는 불가능
df_std1.iloc[df_std1.loc[:,'java']>=85]
3. Series간 연산
population = pd.Series([9602000, 3344000, 1488000, 2419000], index=['서울','부산','광주','대구'])
area = pd.Series({'서울':605.2, '부산':770.1, '광주':501.1, '대구':883.5})
display(population)
display(area)
print(population + area)
print(population - area)
print(population * area)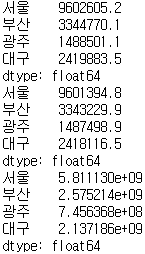
# 인구밀도 = 인구수/면적
dense = population/area
dense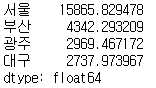
※ pd.concat()을 이용하여 Series 형태인 2020 인구수, 면적(㎢), 인구밀도를 합쳐 DataFrame형태로 만들기
DataFrame의 컬럼명 변경
전체 컬럼 변경 : pd.columns = ['컬럼1','컬럼2',컬럼3',...]
하나씩 지정하여 변경 : 데이터프레임명.rename(columns={'이전컬럼명':'바꿀컬럼명'}, inplace=True)
df = pd.concat([population,area,dense], axis=1)
df.columns = ['2020 인구수','면적(㎢)','인구밀도']
df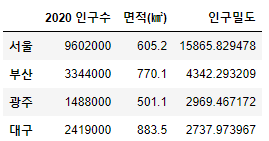
3. Pandas 함수
| .sort_values() | 데이터 값을 기준으로 정렬 (기본값 : 오름차순) .sort_values(by='기준column명') |
| .sort_index() | 인덱스 값을 기준으로 정렬 |
| .value_counts() | 카운팅 |
| .info() | 데이터 정보 확인 |
| .isnull() | 결측치 확인 |
| .sum() | 총합 구하기 |
| .mean() | 평균 구하기 |
| .max() | 최댓값 구하기 |
| .min() | 최솟값 구하기 |
| .cut() | 수치형 데이터를 범주형 데이터로 바꾸기 |
| .groupby() | 데이터를 그룹별로 묶어 집계낼 수 있게 만들기 |
| .drop() | row이나 column 삭제 |
① .sort_values() : 데이터 값을 기준으로 정렬 (기본값 : 오름차순)
# df에서 인구밀도 컬럼만 가져와서 오름차순 정렬
display(df['인구밀도'].sort_values())
# 인구밀도 컬럼을 기준으로 df데이터 오름차순 정렬
display(df.sort_values(by='인구밀도'))
# 인구 밀도 컬럼을 기준으로 df데이터 내림차순 정렬
display(df.sort_values(by='인구밀도', ascending=False))
# 축을 row방향으로 바꿔서 서울 행을 기준으로 df 데이터 오름차순 컬럼 정렬
display(df.sort_values(by='서울', axis=1))
# 축을 row방향으로 바꿔서 서울 행을 기준으로 df 데이터 내림차순 컬럼 정렬
display(df.sort_values(by='서울', axis=1, ascending=False))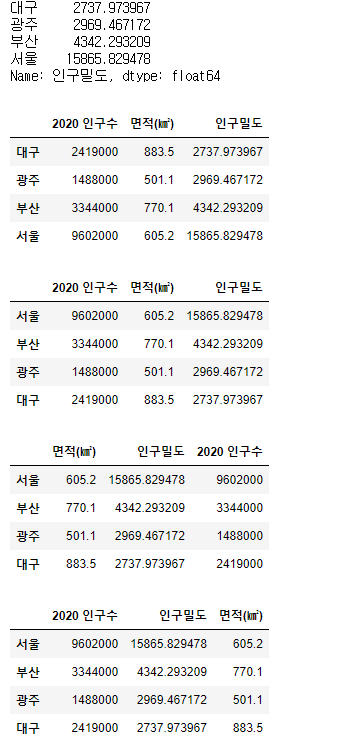
② .sort_index() : 인덱스 값을 기준으로 정렬
# df 데이터에서 면적컬럼만 가져와 index 기준 정렬
display(df['면적(㎢)'].sort_index())
# df 데이터 전체를 index를 기준으로 오름차순 정렬
display(df.sort_index())
# df 데이터 전체를 index를 기준으로 내림차순 정렬
display(df.sort_index(ascending=False))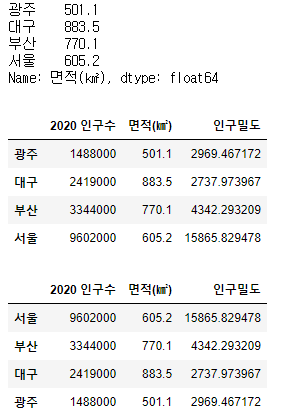
③ .value_counts() : 카운팅
# 면적 데이터 중 같은 값의 데이터 카운트
df['면적(㎢)'].value_counts()
# 데이터에만 접근
df['면적(㎢)'].value_counts().index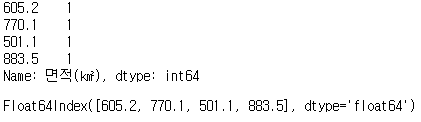
④ .info() : 데이터 정보 확인
※ Pandas 외부 데이터 불러오기
pd.read_파일형식('주소경로')
score = pd.read_csv('./data/score.csv', encoding='euc_kr', index_col='과목')
score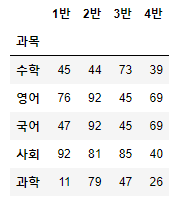
score.info()
⑤ .isnull() : 결측치 확인
display(score.isnull()) # 결측치 확인
display(score.isnull().sum()) # sum()함수로 묶어서 결측치의 개수 구하기
⑥ .sum() : 총합 구하기
# score 데이터의 row방향으로 1반~4반까지의 과목 점수 총합
display(score.sum())
# score 데이터의 학급별 순위
display(score.sum().sort_values(ascending=False))
# score 데이터의 coulumn방향으로 과목별 점수 총합
display(score.sum(axis=1))
# score 데이터에 합계 컬럼을 추가하기
score['합계'] = score.sum(axis=1)
score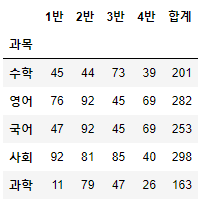
⑦ .mean() : 평균값 구하기
# score 데이터에 과목별 평균 컬럼 추가하기
score['평균'] = score.loc[:,'1반':'4반'].mean(axis=1)
score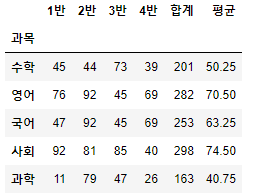
# 반평균을 구해 row에 추가하기
score.loc['반평균'] = score.mean()
score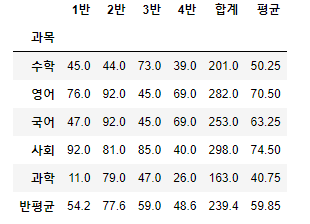
⑧ .max() : 최댓값 구하기, .min() : 최솟값 구하기
# 수학 최고점, 영어 최저점, 국어 최고점, 사회 최저점, 과학 최고점 구하기
print('수학최고점:',score.loc['수학',:'4반'].max())
print('영어최저점:',score.iloc[1,:4].min())
print('국어최고점:',score.loc['국어',:'4반'].max())
print('사회최저점:',score.iloc[3,:4].min())
print('과학최고점:',score.loc['과학',:'4반'].max())
⑨ .cut() : 수치형 데이터를 범주형 데이터로 변환
# 나이에 따른 미성년자, 청년, 장년, 중년, 노년을 구분해서 변환 저장
ages = [0,2,10,21,23,37,31,61,20,41,32,100]
bins = [-1,15,30,40,60,100] # 구간 설정
labels = ['미성년자','청년','장년','중년','노년']
cate = pd.cut(x=ages, bins=bins, labels=labels)
pd.Series(cate)
⑩ .groupby() : 데이터를 그룹별로 묶어 집계낼 수 있게 만들기
s1 = pd.Series([1,0,1,0,1])
s2 = pd.Series(['female','female','male','male','female'])
s3 = pd.Series([1,2,3,4,5])
titanic = pd.concat([s1,s2,s3], axis=1)
titanic.columns = ['Survived','gender','passengerID']
titanic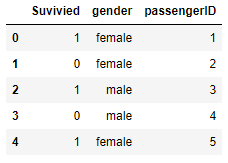
# 성별에 따른 생존자 수 확인하기
# 타이타닉 데이터의 성별과 생존유무 데이터를 가져온 후 gender로 묶기
# 총합(1,0)을 구해 생존자 수 확인
titanic[['gender','Survived']].groupby('gender').sum()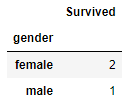
# 성별에 따른 생존자 수 / 사망자 수 확인
titanic.groupby(by=['gender','Survived']).count()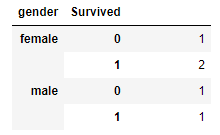
'Python' 카테고리의 다른 글
| 파이썬 크롤링 requests, BeautifulSoup (0) | 2023.01.16 |
|---|---|
| 파이썬 라이브러리 Matplotlib(Python Library Matplotlib) (0) | 2023.01.15 |
| 파이썬 라이브러리 Numpy (Python Library Numpy) (0) | 2023.01.12 |
| 파이썬 함수(Python Function) (0) | 2023.01.10 |
| 파이썬 딕셔너리(Python Dictionary) (0) | 2023.01.08 |




댓글