파이썬 크롤링 requests, BeautifulSoup 네이버 영화 평점 수집 데이터 수집
▶ 목표
- 네이버 영화 > 영화 랭킹 > 평점순 (현재 상영 영화) 데이터를 수집하기
- 페이지를 이동하면서 날짜별(1월12일~1월16일)로 영화명, 평점 데이터를 수집하기
① 필요한 라이브러리 import 및 header 가져오기

import pandas as pd
import requests as req
from bs4 import BeautifulSoup as bs
header = {'user-agent':'mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/109.0.0.0 safari/537.36 edg/109.0.1518.52'}
② 웹 주소경로 url과 날짜 데이터 전처리 및 포맷
※ 웹 주소 경로 날짜 확인

# url 주소, 날짜 생성하기
# data_lst = ['20230112',...,'20230116']
create_date = pd.date_range(start='2023-01-12', period)
date_list = [i.strftime('%Y%m%d') for i in create_date]
date_list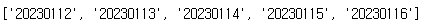
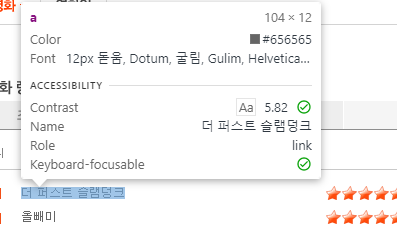
③ 영화명, 영화평점의 text가 있는 태그 확인
영화명

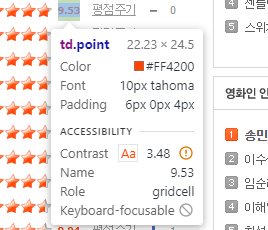
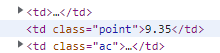
영화 평점
④ for문을 이용하여 필요한 데이터를 모두 수집하기
# 2023.01.12 ~ 2023.01.16까지(5일치) 웹페이지 요청
day_lst = []
for date in date_list :
url = 'https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&tg=0'
# url 경로에 params 속성을 이용하여 date 넣어주기
res = req.get(url, headers=header, params={'date':date})
# url 확인
print(res.url)
# 파이썬 객체 변환
html = bs(res.text,'lxml')
# 영화명, 영화 평점
# for~text를 추출하여 list 저장
movie_name = html.select('.tit5>a')
movie_point = html.select('.point')
rank_lst = [i+1 for i in range(len(movie_name))]
for i in range(len(movie_name)):
name = movie_name[i].text
point = movie_point[i].text
rank = rank_lst[i]
day_lst.append([date,rank,name,point])
⑤ 수집한 데이터를 Pandas DataFrame형태로 만들기
movie_df = pd.DataFrame(day_lst, columns=['날짜','랭킹','제목','평점'])
movie_df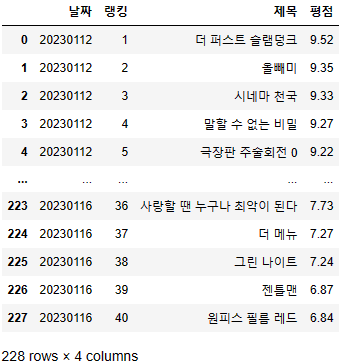
'Python' 카테고리의 다른 글
| 파이썬 크롤링 selenium 네이버 검색 해보기, 한솥 도시락 메뉴 정보 수집 (0) | 2023.01.21 |
|---|---|
| 파이썬 크롤링 requests, BeautifulSoup 네이버 영화 관람객 리플 데이터 수집 (1) | 2023.01.19 |
| 파이썬 크롤링 requests, BeautifulSoup 멜론 Top100 차트 데이터 수집 (0) | 2023.01.18 |
| 파이썬 크롤링 requests, BeautifulSoup (0) | 2023.01.16 |
| 파이썬 라이브러리 Matplotlib(Python Library Matplotlib) (0) | 2023.01.15 |




댓글