파이썬 크롤링 requests, BeautifulSoup
1. requests 라이브러리
- 페이지의 정보 요청/응답
- import requests as req
url = 'https://www.naver.com/'
# 네이버 페이지 요청
# url에 저장되어 있는 웹문서 요청하기!
# <Response [200]> 성공적으로 요청/응답이 진행된 상태
res = req.get(url)
res
# 문자열 -> txt
res.text
2. BeautifulSoup 라이브러리
- 웹 문서 안에 있는 태그 데이터를 추출할 수 있도록 함수를 제공하는 라이브러리
- 웹 문서(문자열) → 파이썬 객체 변환
- 함수를 통해 원하는 정보에 접근
- from bs4 import BeautifulSoup as bs
# 웹 문서(res.text) -> 파이썬 객체 변환
# bs(웹문서데이터, 변환도구)
html= bs(res.text,'lxml')
html
| .select_one('css선택자') | css 선택자에 맞는 html 객체 접근 |
| .select('css선택자') | 여러 개의 css 선택자에 맞는 html 객체 접근 |
| .text | 태그 안에 있는 문자 데이터 접근 |
# html.select_one('css선택자') : css선택자에 맞는 html 객체 접근
# css 선택자
# 아이디선택자 : #아이디명
# 클래스선택자 : .클래스명
# 태그선택자 : 태그명
# 계층선택자(자식(>), 자손(공백), 형제(~), 인접형제(+))
html.select_one('title').text
# 태그 안에 있는 문자 데이터 접근 : .text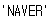
▶ 연습
.select_one('css선택자')를 이용해 네이버에서 겨울 축제를 검색한 후 축제명 1개 데이터를 가져와보기
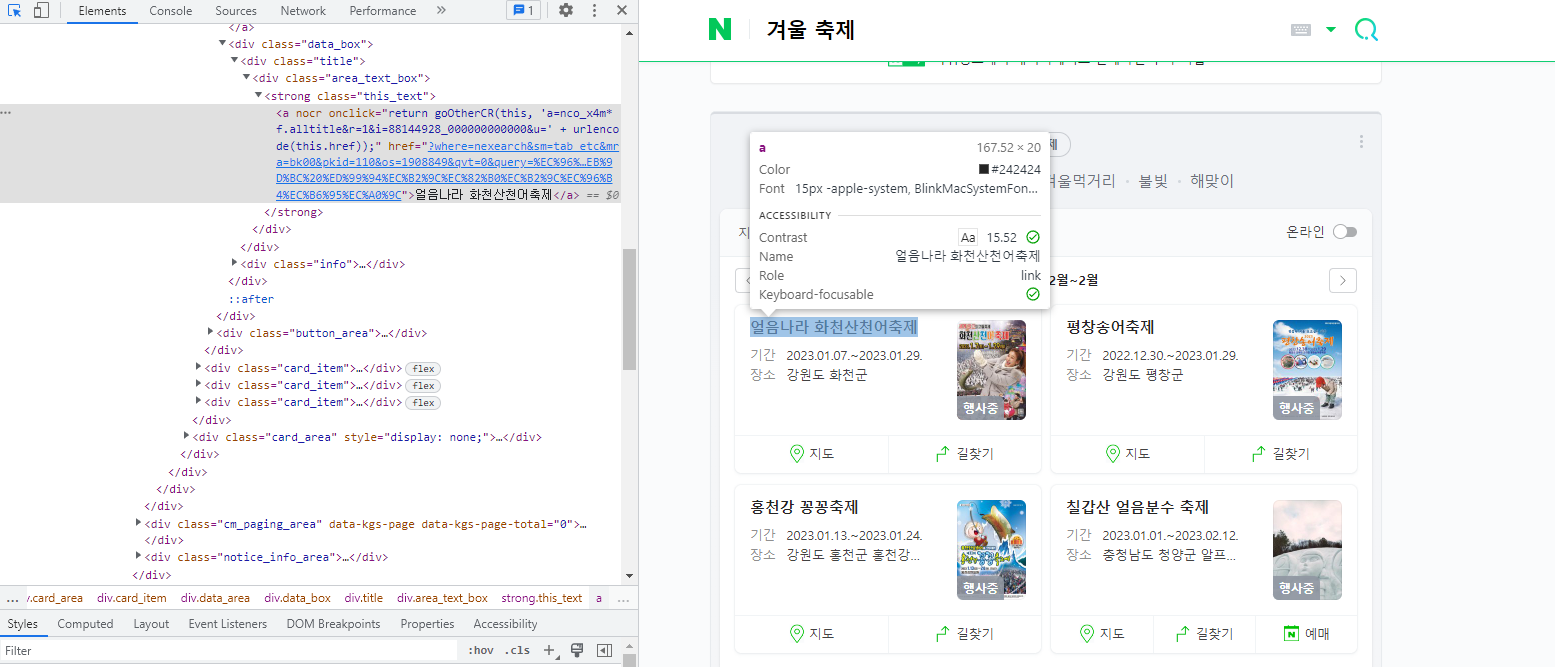
url2 = 'https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%EA%B2%A8%EC%9A%B8+%EC%B6%95%EC%A0%9C'
res = req.get(url2)
html2 = bs(res.text,'lxml') # 파이썬 객체 변환
print(html2.select_one('.this_text>a').text)
▶ 연습
.select('css선택자')를 이용해 여러 개의 축제 이름을 동시에 가져오기
# 여러 개의 축제 이름 접근해보기
ft_list = html2.select('.this_text>a')
# 축제 이름 문자열만 추출해보기
ft_list
# for문을 이용해서 축제 이름 데이터를 1개씩 가져오기
for i in ft_list :
print(i.text)for i in range(len(ft_list)) :
print(ft_list[i].text)
3. 네이버에서 뉴스 가져오기
- requests header 설정하기
컴퓨터에게 브라우저에서 요청했다는 인식을 주기 위한 설정
크롤링할 때 모든 페이지 요청 시 header 설정하고 갈 것
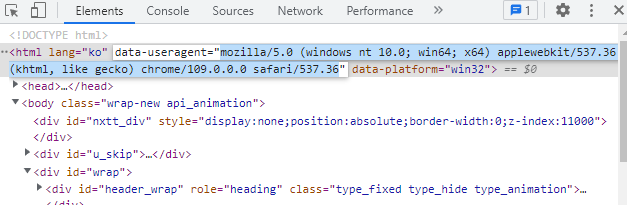
값 : 개발자 도구 맨 위 useragent
header = {'user-agent' : 값}
req.get(url, headers=header)
# requests, BeautifulSoup 불러오기
import requests as req
from bs4 import BeautifulSoup as bs
# 네이버 뉴스 > 생활/문화 탭 > 기사 하나 선택
news_url = 'https://n.news.naver.com/mnews/article/052/0001838287?sid=103'
# 요청/응답 확인
# res = req.get(url)
# res
# 컴퓨터에게 브라우저에서 요청했다는 인식을 주기 위한 설정
# 크롤링 시에 모든 페이지 요청 시 header 설정하고 갈 것
header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
res = req.get(url, headers=header)
res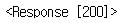
# 태그 데이터 접근 > 파이썬 객체 변환
html3 = bs(res.text,'lxml')
# 기사 제목, 기사 내용(문자)
title = html3.select_one('h2>span').text
content = html3.select_one('#dic_area').text
print(title)
print(content.strip()) # .strip() 양쪽 공백 제거
'Python' 카테고리의 다른 글
| 파이썬 크롤링 requests, BeautifulSoup 네이버 영화 평점 수집 데이터 수집 (0) | 2023.01.18 |
|---|---|
| 파이썬 크롤링 requests, BeautifulSoup 멜론 Top100 차트 데이터 수집 (0) | 2023.01.18 |
| 파이썬 라이브러리 Matplotlib(Python Library Matplotlib) (0) | 2023.01.15 |
| 파이썬 라이브러리 Pandas (Python Library Pandas) (0) | 2023.01.15 |
| 파이썬 라이브러리 Numpy (Python Library Numpy) (0) | 2023.01.12 |




댓글